OpenAI’s latest GPT-5.4 Pro model has now achieved an IQ score higher than 99.96% of all human beings, giving markets a fresh signal that AI capability gains are starting to outpace the usual product-cycle noise.
OpenAI’s GPT-5.4 Pro touches 150 on public IQ benchmark as markets enter another macro-heavy week
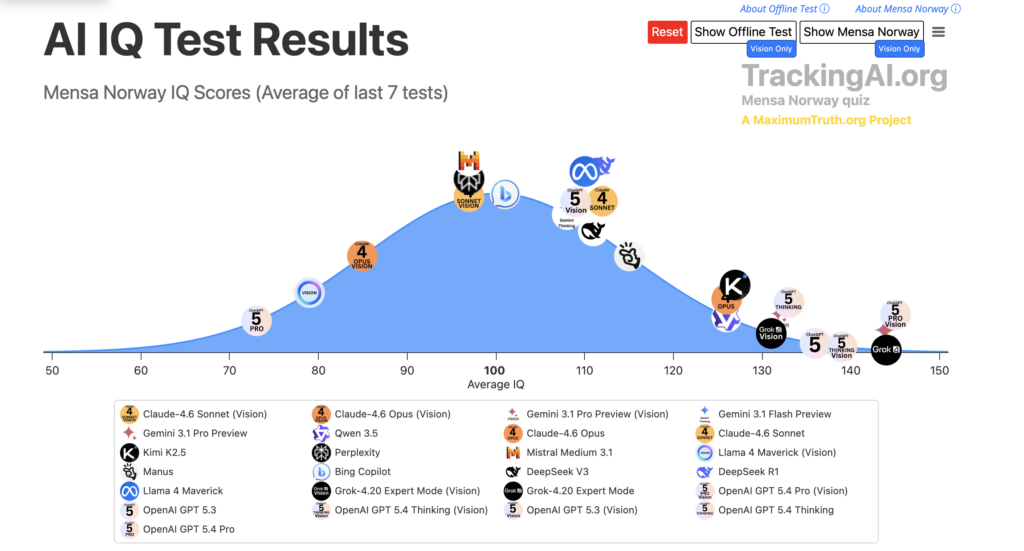
TrackingAI’s public leaderboard now places OpenAI GPT-5.4 Pro at an IQ score of 150, a sharp step up from the 136 score that OpenAI’s o3 posted on the Mensa Norway test last year.
The jump arrives at a moment when market attention has narrowed around Iran, energy, labor softness, and the next inflation print. That creates a different question for the week ahead: how quickly is machine intelligence compounding, and when will that acceleration begin to overlap with economic positioning?
Why this matters: A move from 136 to 150 on a widely understood benchmark compresses a complex capability shift into a simple signal. For businesses, that signal feeds directly into decisions around automation, software budgets, and headcount planning. For markets, it adds another variable alongside rates, inflation, and growth expectations.
OpenAI introduced GPT-5.4 as its most capable and efficient frontier model for professional work, with stronger coding, tool use, and computer use, and a context window of up to 1 million tokens. In the same release, OpenAI said GPT-5.4 achieved a new state of the art on GDPval and exceeded human performance on OSWorld-Verified.
Those benchmarks are separate from a public IQ test, yet the direction of travel aligns. Capability is rising across separate measurement systems, and that rise is becoming fast enough to influence budgeting, hiring plans, workflow design, and software spend.
A score of 150 on a public IQ-style benchmark compresses a broader capability move into a single, portable signal. The number is easy to understand even before the methodology is debated.
The earlier o3 Mensa result established the benchmark and its limits. GPT-4.1’s one-million-token context window showed how OpenAI was extending model utility across long-horizon code and document tasks, while our analysis of OpenAI’s expanding capital loop linked model progress to hardware expansion, financing loops, and infrastructure demand.
Taken together, those developments place the latest IQ score within a broader commercial and economic context. A move from 136 to 150 on a public benchmark is striking on its own. A move from 136 to 150 while OpenAI is pushing deeper into tool use, computer use, enterprise productivity, and capital-intensive infrastructure carries broader implications.
Public IQ benchmarks are limited, but the capability curve is still moving higher
Public IQ-style tests remain imperfect instruments for measuring frontier models. TrackingAI runs a public Mensa-style benchmark and also maintains a harder private offline test.
IQ-style tests compress a narrow slice of cognitive performance into a single number, obscuring variation across reasoning types, context handling, creativity, and real-world problem-solving.
For AI and humans alike, scores are sensitive to test design, training exposure, and pattern familiarity, which makes them a noisy proxy for general capability.
An IQ of 150 sits at the extreme upper tail of the distribution, often associated with individuals such as Albert Einstein or Richard Feynman. In practical terms, it implies very fast abstraction, strong pattern recognition, and the ability to navigate complex, multi-step problems with limited guidance.
The platform reports scores as rolling averages across recent completions, and the methodology raises familiar questions around prompt structure, reproducibility, training-set contamination, and format familiarity. Those concerns were already visible when o3 reached 136, and they remain active now that GPT-5.4 Pro sits at 150.
Even with those limits, the broader pattern has become harder to dismiss. One isolated benchmark result can be explained away as a quirk. A cluster of gains across public IQ-style testing, coding, browser use, desktop navigation, and knowledge-work performance carries more analytical weight.
TrackingAI’s latest leaderboard places GPT-5.4 Pro at the top of its public IQ board ahead of all Cluade, Gemini, Qwen, and Grok models, offering an external, legible public benchmark that maps quickly onto the broader capability debate.
Few people need a detailed understanding of benchmark design to grasp that 150 sits in a rare range and investors do not need to accept every premise behind an IQ-style test to recognize that a jump of this size suggests acceleration rather than drift.
Chart titled “AI IQ Test Results” showing average Mensa Norway IQ scores for major AI models on a bell curve, with OpenAI’s GPT-5.4 variants plotted near the top end of the range.
Enterprise buyers also do not need to believe that IQ equals general intelligence to see that systems with stronger pattern recognition, stronger tool use, and stronger long-horizon task handling are moving toward economically useful territory, extending far beyond puzzle-solving.
This points toward systems that can search, plan, verify, navigate, and produce real work across extended contexts. In that setting, the IQ score functions less as a novelty number and more as a signal of the density of frontier reasoning.
There is also competitive value in the leaderboard itself. A leadership position on a public benchmark reinforces OpenAI’s standing in the race for visible capability leadership, especially at a moment when model differentiation is becoming harder to discern from architecture notes alone.
Benchmark leadership compresses complexity into a simple hierarchy. It offers developers a signal, enterprise buyers a narrative handle, and investors another proxy for where the capability frontier currently sits.
CryptoSlate Daily Brief
Daily signals, zero noise.
Market-moving headlines and context delivered every morning in one tight read.
5-minute digest 100k+ readers
Free. No spam. Unsubscribe any time.
Whoops, looks like there was a problem. Please try again.
You’re subscribed. Welcome aboard.
OpenAI’s benchmark climb is beginning to overlap with the economic week ahead
That schedule keeps rates, inflation, and growth anxiety in the foreground, but beneath that surface, a second economic track is taking shape, and OpenAI sits near its center.
Capability growth in frontier AI increasingly intersects with capital allocation. A model that pushes higher on public reasoning tests while also improving in coding, search, and computer use changes how businesses think about workflow redesign. It changes what software buyers expect from copilots and agents. It changes how quickly enterprises move from experimentation toward deployment.
Jack Dorsey recently posted that Block is moving “from hierarchy to intelligence,” using AI to take over coordination work once handled by management layers as the company reorganizes around individual contributors, directly responsible individuals, and player-coaches
Capability growth also changes which tasks can be carved out of labor cost structures and reassigned to software. These effects move through narrower channels first, including document workflows, spreadsheet workflows, customer support, research tasks, browser automation, internal operations, code generation, and verification loops.
OpenAI’s commercial direction reinforces that interpretation. In its GPT-5.4 launch materials, the company described stronger performance in professional work, stronger tool search, native computer use, and gains in benchmarked knowledge work across occupations that map directly onto the U.S. economy.
That places AI capability growth inside a familiar market question, where spending flows next if these systems continue improving at this pace.
The answer extends beyond model subscription revenue into cloud demand, chips, data centers, networking, power, software licenses, and labor productivity assumptions. OpenAI’s expanding capital loop already reflects part of that structure, and the benchmark gain adds a simpler public-facing signal on top of it.
That overlap is what gives the latest result broader relevance during a macro-heavy week. Markets already know the CPI setup. Markets already know oil prices can feed into inflation expectations. Markets already know the Fed minutes will be parsed for policy tone.
But is the growth in intelligence itself beginning to behave like a macro variable? Faster capability gains can alter enterprise spending plans, tighten competitive pressure across white-collar functions, support higher infrastructure outlays, and strengthen the case for AI-linked capital expenditure even in a slower nominal growth environment.
When TrackingAI shows GPT-5.4 Pro at 150, the number falls within a market that already views OpenAI as more than a lab. It is a platform company, a deployment company, an infrastructure customer, and a signal generator for adjacent sectors.
The next test sits in two places at once. One is methodological; public IQ-style benchmarks will keep drawing scrutiny, and they should. The other is economic; markets will decide, step by step, whether capability jumps of this size deserve to be priced alongside labor data, rate expectations, and capital spending trends.
OpenAI’s latest benchmark climb pushes that decision closer. The score is compact, legible, and easy to circulate. Its deeper relevance comes from the same place as the company’s broader product push; the frontier is still climbing, and the economic footprint of that climb is becoming harder to keep in a separate category.